Toward a better programming
27 Mar 2014 - Chris Granger
this post is based on my talk, “Finding a way out”, from Strange Loop 2013
When I built the original prototype of Light Table I didn’t have any grand purpose or goal in mind. I simply had some ideas on how programming could be better and I wanted to see how hard they would be to build. Until fairly recently, it never dawned on me that I’ve actually spent the past decade trying out ideas on how programming could be better, from web frameworks, to Visual Studio, to Light Table and its future. And it wasn’t until I had that realization that I also came to the conclusion that I’d been going about this all wrong. As a matter of fact, I made a classic rookie mistake: I set out to answer a question I didn’t understand.
How do we make programming better?
I kept asking myself “How can we make programming better?”, but I never took a step back and concretely figured out what’s wrong with programming. I’ve always been very reactionary to either my own work or the observations I had of others, and it turns out that has continually led me to local maxima. With Light Table for example, I thought shortening the feedback loop would make a tremendous difference, and while it does make a big impact, it’s overshadowed by the fact that it’s the same old broken version of programming. People still struggled. I still struggled. It didn’t deliver us from the incredible frustration that is writing and debugging software. So if it’s not just the feedback loop, what is it then? What’s wrong with programming?
To answer that I needed more data, not just from my time behind one way mirrors or my own experiences, but from the “real world”. So I started asking everyone who would talk to me two questions: “What is programming and what’s wrong with it?” I talked to people who had never programmed a day in their life, people in the middle of their careers, and even some of the best engineers in the industry. And what I found surprised me.
What is programming?
The answers I got to this were truly disheartening. Not once did I hear that programming is “solving problems.” Instead, I found out that it’s just clumping things together with half-dried glue and praying that it holds water long enough to replace it with a new clump of things. I heard over and over again that we’re plumbers and glue factories, that programming is largely about working around its own deficiencies. This is particularly sad to me, because it turned out to be the only real commonality among the answers: we plumb things together to get something that kind of works. And the “kind of works” part is the source of an unbelievable amount of frustration.
Programming should be about solving problems, but somewhere along the way it turned into us solving the problems around our problems (a friend and ridiculously good engineer likes to call this a “self licking ice cream cone”). The glue factory answer certainly isn’t a desirable one, so I’ve been trying to come up with something workable since. The one I like the best so far is that programming is our way of encoding thought such that the computer can help us with it. At the end of the day, what we’re trying to do is build something that enables us to accomplish something new - programming just happens to be the way we talk to the computer to get it done.
And what’s wrong with it?
The answers to this were why I ended up talking to so many people (around 400 in the end). They tended to fall into one of two categories: they were either so general that they didn’t really provide any information, or they were so tactical that they didn’t apply to anyone else (I get these deadlocks when I’m…). In aggregate, though, some patterns emerged and after hundreds of answers I was able to distill almost everyone’s issues into three buckets for what’s wrong with programming. Those buckets were that it is unobservable, indirect, and incidentally complex.
Programming is unobservable
This one seems to be getting the most attention lately thanks to Bret and our work on Light Table. We can’t see how our programs execute. We can’t see how our changes affect our programs. And we can’t see how our programs are connected together. That basically means we can’t observe anything. The state of the art in observability is a stepwise debugger, which forces us to stop the world and look at a single instant in time. But the truth is that few errors occur in an instant; most are found only by observing the passage of time. And for that, the best we have is print statements. This is ridiculous. We should be able to observe the entire execution of our program, forward, backward, even branched into new futures - not just when our breakpoint hits. Even sadder than that though, is that we seem to have embraced unobservability as an industry best practice. Think about a line of code like this:
person.walk();
What does it do? OOP’s notion of encapsulation is by definition unobservable. I have no idea what person.walk() does. It probably does something sane, like set isWalking to true, but it could also be setting ateCarrots to true and it may have determined that I passed out from exhaustion - I have no idea and no way to tell. We are quite literally throwing darts in the dark and praying that we at least hit the board. We simply cannot see what our programs do and that’s a huge problem whether you’re just starting out or have written millions of lines of beautiful code.
Programming is indirect
Writing a program is an error-prone exercise in translation. Even math, from which our programming languages are born, has to be translated into something like this:
#include <algorithm>
#include <iostream>
#include <iterator>
#include <cmath>
#include <vector>
#include <iterator>
#include <numeric>
template <typename Iterator>
double standard_dev( Iterator begin , Iterator end ) {
double mean = std::accumulate( begin , end , 0 ) / std::distance( begin , end ) ;
std::vector<double> squares ;
for( Iterator vdi = begin ; vdi != end ; vdi++ )
squares.push_back( std::pow( *vdi - mean , 2 ) ) ;
return std::sqrt( std::accumulate( squares.begin( ) , squares.end( ) , 0 ) / squares.size( ) ) ;
}
int main( ) {
double demoset[] = { 2 , 4 , 4 , 4 , 5 , 5 , 7 , 9 } ;
int demosize = sizeof demoset / sizeof *demoset ;
std::cout << "The standard deviation of\n" ;
std::copy( demoset , demoset + demosize , std::ostream_iterator<double>( std::cout, " " ) ) ;
std::cout << "\nis " << standard_dev( demoset , demoset + demosize ) << " !\n" ;
return 0 ;
}
Why do we have to see that, instead of this?
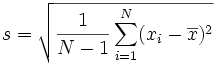
And that’s with something that at least translates fairly cleanly. What happens when it doesn’t? All we get in code are symbols. We never see or interact with the real things, just symbolic representations of them. While symbols are certainly important and powerful in some cases, they don’t have to be this opaque:
cards[0][12]
Ah yes, when playing cards, I love it when I get the cards[0][12]. We’re writing a card game and cards have real representations, so why can’t we just see this instead?

Translation is hard and using symbols is error-prone, especially coupled with operations on top of other symbols. This indirectness, this inability to represent things usefully and directly manipulate them, is killing us. A vast number of programming errors are simple translation problems. We had the solution in our head, but in trying to turn it into code we just forgot something or translated it very slightly wrong. We have to get away from that translation. When we do UI, we should do it in a visual editor. When we do math, we should have something like Mathematica at our fingertips. We should express domains in the ways they most naturally present themselves in, not with our own homegrown obfuscations.
Programming is incidentally complex
There is an immense amount of incidental complexity in writing software, by which I mean there’s a bunch of work that needs to be done that isn’t directly related to the real problem you’re trying to solve. Just think about how long it takes to even get something simple to run or the fact that people can spend the better part of a week just trying to set up a dev machine from scratch. These are some simple examples of unnecessary complexity at a systems level, but the truth is incidental concerns are pervasive throughout the entire process of writing software. One of the worst for us right now is at the logic level - managing time in our code. Most people tend to jump immediately to concurrency and parallelism when I say that, but it’s actually more fundamental than that. Every time we add an event handler or create a callback, we’re doing time management. We’re saying at some point later we want this code to execute. Considering the increasingly more complex schemes of interaction that our programs have on top of the proliferation of multiple cores (and the very real concurrency problems that brings), we’re quickly learning that callbacks are a terrible solution to this problem. Every time we’ve found ourselves manually managing something, we’ve come up with a solution that does it for us. We were manually handling binary and so we created Fortran. We were managing memory and so we created garbage collectors. We were managing data constraints and so we got type systems. I think the next big step in terms of removing incidental complexity in code will come from automatically managing time. The implications of which would be tremendous for our ability to cleanly express intent.
There are so many examples of incidental complexity in programming it would be disheartening to try and enumerate all of them, but we have to start addressing them at some point. We should be focused on solving our problems - not solving the problems around solving our problems. At the end of the day, we should be able to go from nothing to a solution in the time it takes us to think of one, not the weeks and months it takes us now.
Chasing local maxima
If you look at much of the advances that have made it to the mainstream over the past 50 years, it turns out they largely increased our efficiency without really changing the act of programming. I think the reason why is something I hinted at in the very beginning of this post: it’s all been reactionary and as a result we tend to only apply tactical fixes. As a matter of fact, almost every step we’ve taken fits cleanly into one of these buckets. We’ve made things better but we keep reaching local maxima because we assume that these things can somehow be addressed independently. The best analogy I’ve heard for what this has resulted in is teacups stacked on top of teacups. Each time we fix something, we push ourselves up some, but eventually we’re working under so many layers of abstraction that the tower starts to lean and threatens to fall down. We have to stop thinking about these issues individually, and instead start imagining what it would take to address them all simultaneously.
The other day, I came to the conclusion that the act of writing software is actually antagonistic all on its own. Arcane languages, cryptic errors, mostly missing (or at best, scattered) documentation - it’s like someone is deliberately trying to screw with you, sitting in some Truman Show-like control room pointing and laughing behind the scenes. At some level, it’s masochistic, but we do it because it gives us an incredible opportunity to shape our world. With a definition for what programming is and a concrete understanding of what’s wrong with it, we have a framework for capturing that opportunity and removing the rest. But in order to do so, we can’t just bolt it on to what we have now. Another layer of abstraction won’t be enough. Instead, we have to address these fundamental problems at the very foundation of our solution. No more teacups and no more compromises.
The people’s programming
I mentioned when I talked with folks that I talked to non-programmers too. I did so because they would provide a very different view and the truth is that most of them are programmers by my definition. They just don’t happen to write “code”. If you use Excel, you’re programming - you’re getting the computer to do work for you based on a process you’ve encoded for it. Excel provides a particularly interesting example, given that it has been massively successful at enabling people to solve problems. It also happens to address all three of our fundamental issues and gives us some evidence that doing so can create an incredibly powerful and approachable environment for people to work in. Excel is inherently observable since it doesn’t have any hidden state and all values are there for you to see and manipulate. It’s also direct. You change values in the grid, drag drop things, do calculations on selections, and so on. And it manages to sidestep a lot of incidental complexity; spreadsheets are timeless, without setup, and don’t even have a notion of being run. Excel achieves this, however, by making a tradeoff in power. There are a lot of things it cannot express very well (or at all) because of the constraints placed on the programming model. The interesting question is whether we can solve our issues in a similar way, but ease some of the constraints to retain more power.
The more we’ve explored this stuff, the more we’ve realized that fixing these problems goes a long way toward making programming more generally palatable. So if the answer to that interesting question ends up being yes, you’d have an environment that gives just shy of a billion people the equivalent of modern day super powers. Imagine what it would be like if virtually everyone with a computer could command it to do even 80% of what a programmer can today. What would the impact of that be? I haven’t the slightest idea, but the more I’ve considered it the more I’ve realized it would be a fundamental shift in what we as a collective would be capable of and that’s certainly a fascinating thing to consider. In the long run, I do believe manipulating computers will be a fundamental skill, but unlike most of the “programming is literacy!” movements lately, I think it’ll have very little to do with writing out “if” statements. The best path forward for empowering people is to get computation to the point where it is ready for the masses. Any attempt to do so with what we have now is destined to fail. It turns out masochism is a hard sell.
A note on culture
One thing my buckets didn’t address is the more societal issues around programming, which are getting a lot of attention lately. There are numerous facets to this problem from the image that programming has, to the way our communities interact, to the biases and prejudices that have developed. I think one of the most interesting aspects to a complete rethinking of programming is the potential for a reboot in the culture of technology. What would it mean if programming wasn’t inherently antagonistic? What would it be like if the only prerequisite for getting a computer to do stuff was figuring out a rough solution to your problem? What if programming was inclusive from the start? In many ways I sincerely hope that whatever way things go, it looks nothing like what we consider programming now. Because the impact of deliberately addressing some of the cultural issues that have developed could be truly world changing.
Great, now what?
We find a foundation that addresses these issues! No problem, right? In my talk at Strange Loop I showed a very early prototype of Aurora, the solution we’ve been working on to what I’ve brought up here. While our strategy has changed significantly since that demo, the notions behind it remain the same - we’re out to find something better, something that isn’t just for programmers or non-programmers, but instead removes that distinction entirely. We’ve made some very real progress in that direction lately, and we’ll be sharing more as it solidifies. But one thing I will say is that what’s coming will have to be seen to be believed.